KIbaroP - AI-based robust production planning
Motivation
In the manufacturing industry, improving disruption avoidance is critical as production becomes increasingly susceptible to disruptions. In industrial practice, disruptions are currently not taken into account in production planning or are only considered by adding estimated surcharges (e.g., 10 to 20 % of the lead time) to the planned lead time. These surcharges are used to increase on-time delivery despite any disruptions. However, there is a risk that excessively long lead times will result in reduced customer satisfaction, higher storage costs, and reduced productivity.
Objective
Considering the specific challenges of small and medium-sized enterprises (SMEs), such as limited data availability, a robust artificial intelligence (AI)-based approach to production planning is being developed and validated. In this context, disturbances resulting from personnel, materials, operating resources, warehouse, process, and IT are considered situationally and preventively in production planning. To this end, existing data from production (e.g., movement data, machine data) are to be considered and aggregated with data from the operational system landscape so that the information base on disruptions to the production system can be used in production planning. For this purpose, historical and current feedback data (e.g., quality data, real-time data, current production sequence) will be used to assess the risk of disruptions in individual operations. Based on this, time buffers for orders will be dimensioned so that potential disruptions can be compensated for in advance. The information obtained is processed utilizing AI approaches to make statements about critical orders or workplaces regarding their susceptibility to disruptions, among other things. The results of the data-driven modeling of disruptions are used for robust production planning.
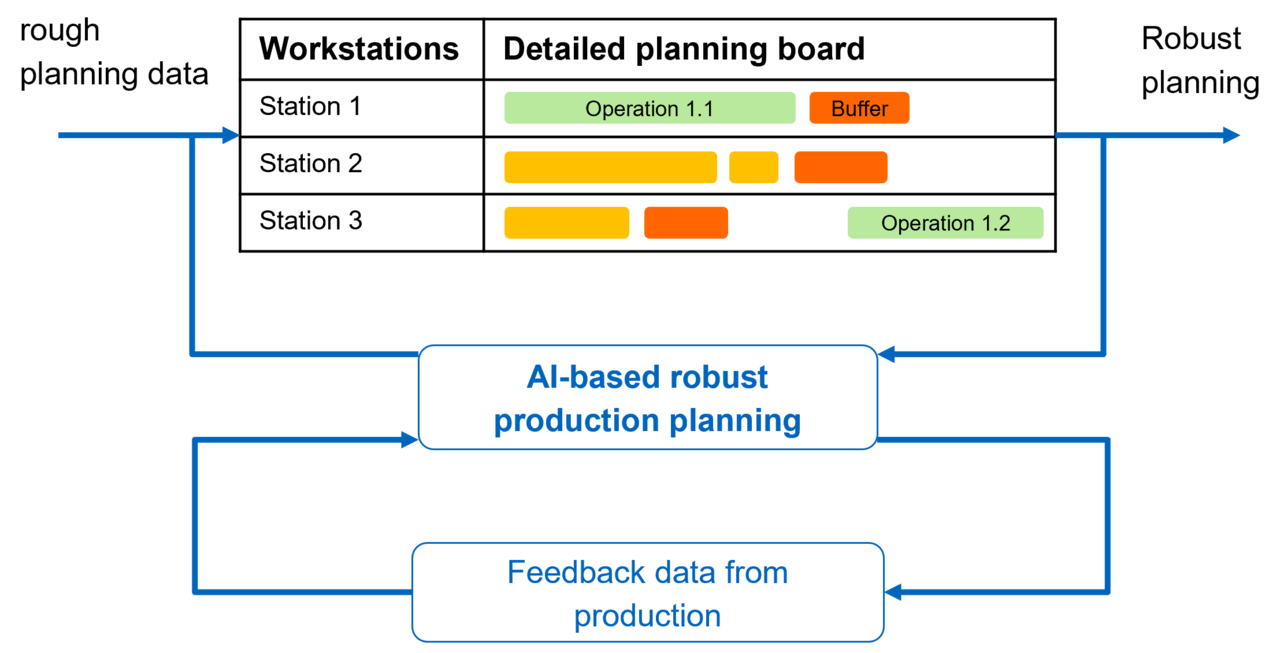
Research Procedure
The solution approach is based on the industry-oriented process CRISP-DM (Cross Industry Standard Process for Data Mining) to develop a practical solution as a software demonstration application for SMEs. This application considers order, feedback, and other data from the operational system landscape and socio-technical environment. The basis for applying AI is the available data for AI algorithm training. Therefore, the proposed solution involves merging diverse data sources to attain a maximally comprehensive database. First, literature-based correlations between feedback data from production and various types of faults are identified. These correlations will then be validated in collaboration with the participating SMEs and used to build a generic simulation model that maps the correlations between disturbance types and feedback data. The generic simulation model will then be used to generate synthetic feedback data sets that can be used with the SME feedback data as a training data set for the AI algorithms. Based on this dataset, the next step is to develop an AI model to predict failures and integrate it with the SME's existing PPS. Subsequently, the results will be evaluated and used to create a demonstrator. Dealing with challenges in production planning resulting from a small amount of data is achieved by combining the data provided by the SMEs with synthetic data, as this means that even a tiny database at the SMEs is sufficient.